SpawnDev.ILGPU
4.12.0
dotnet add package SpawnDev.ILGPU --version 4.12.0
NuGet\Install-Package SpawnDev.ILGPU -Version 4.12.0
<PackageReference Include="SpawnDev.ILGPU" Version="4.12.0" />
<PackageVersion Include="SpawnDev.ILGPU" Version="4.12.0" />
<PackageReference Include="SpawnDev.ILGPU" />
paket add SpawnDev.ILGPU --version 4.12.0
#r "nuget: SpawnDev.ILGPU, 4.12.0"
#:package SpawnDev.ILGPU@4.12.0
#addin nuget:?package=SpawnDev.ILGPU&version=4.12.0
#tool nuget:?package=SpawnDev.ILGPU&version=4.12.0
SpawnDev.ILGPU

Run ILGPU C# kernels on WebGPU, WebGL, Wasm, Cuda, OpenCL, and CPU - from a single codebase.
Write parallel compute code in C# and let the library pick the best available backend automatically. In the browser, three backends (WebGPU, WebGL, Wasm) bring GPU-accelerated compute to virtually every modern browser. On desktop and server, ILGPU's native Cuda and OpenCL backends are available alongside CPU. The same async extension methods work everywhere.
Your existing ILGPU kernels run in the browser with zero changes to the kernel code - and the same code runs on desktop too.
Recent Highlights
4.10.0 (current): Wasm multi-worker correctness overhaul - the large-sort / barrier race family is dead (verified atomic stores + liveness-reduced, checksum-gated spill restore; WasmTests 510/510). Precompiled shaders - generate a kernel's WGSL/GLSL/Wasm offline with no device on any host OS, precompile at build time via an MSBuild task, and load the artifact at runtime to skip IL->shader transpilation. Plus WebGPU GridDim.X > 65535 2D-grid auto-tile, WebGL Half RadixSort, and Float16/Float64/Int64 reported on every backend (emulated where not native). Bundles forks 2.0.15.
See CHANGELOG.md for the full per-version history - every release, code samples, and per-backend implementation detail.
Architecture
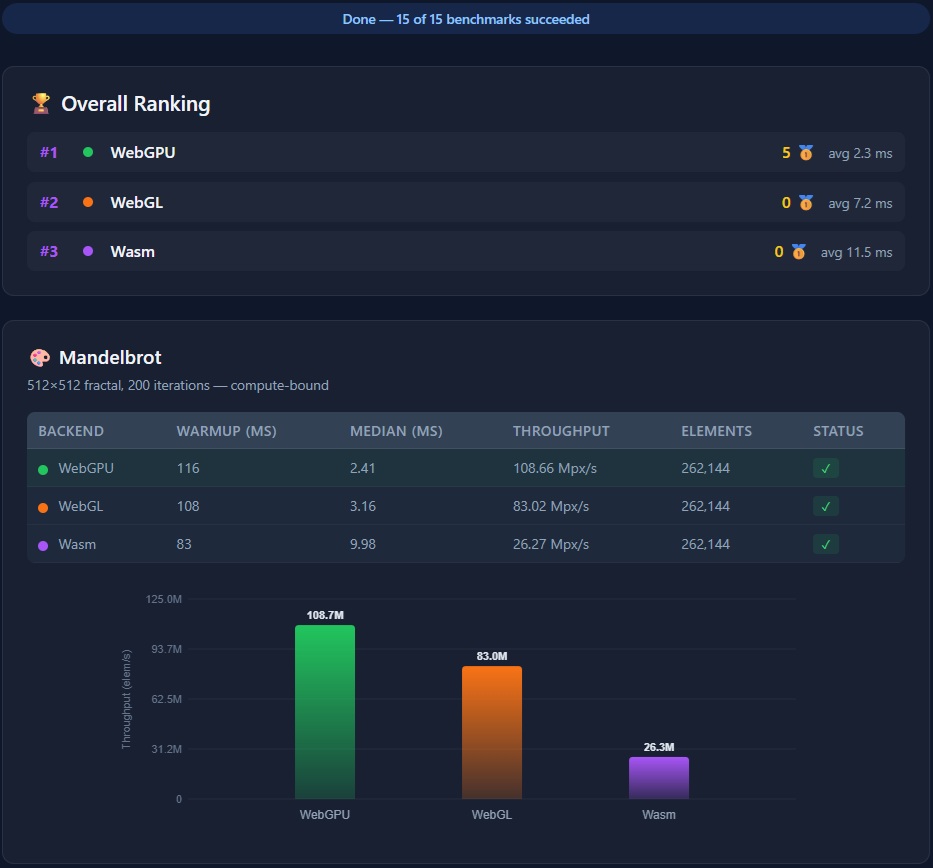
Browser backends (Blazor WebAssembly) - auto-selected: WebGPU → WebGL → Wasm
| WebGPU | WebGL | Wasm | |
|---|---|---|---|
| Compiles to | WGSL | GLSL ES 3.0 | Wasm binary |
| Runs on | GPU | GPU | Web Workers |
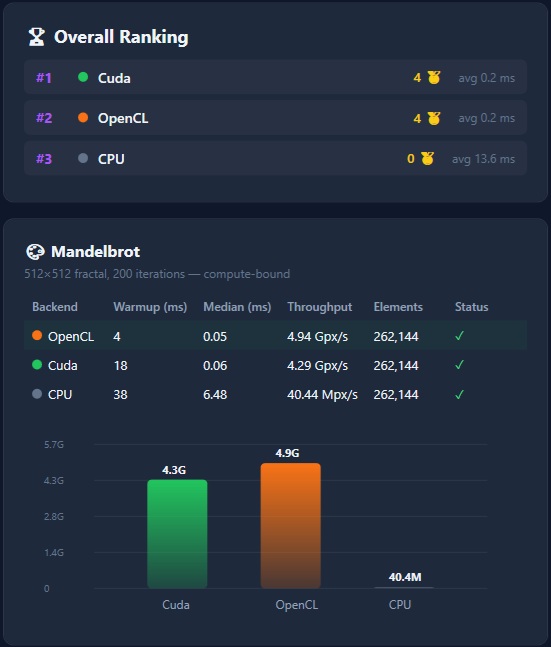
Desktop backends (Console, WPF, ASP.NET) - auto-selected: Cuda → OpenCL → CPU
| Cuda | OpenCL | CPU | |
|---|---|---|---|
| Compiles to | PTX | OpenCL C | - |
| Runs on | NVIDIA GPU | Any GPU | CPU cores |
Demo Applications
Browser Demo (Blazor WebAssembly)
The Live Demo source is in SpawnDev.ILGPU.Demo:
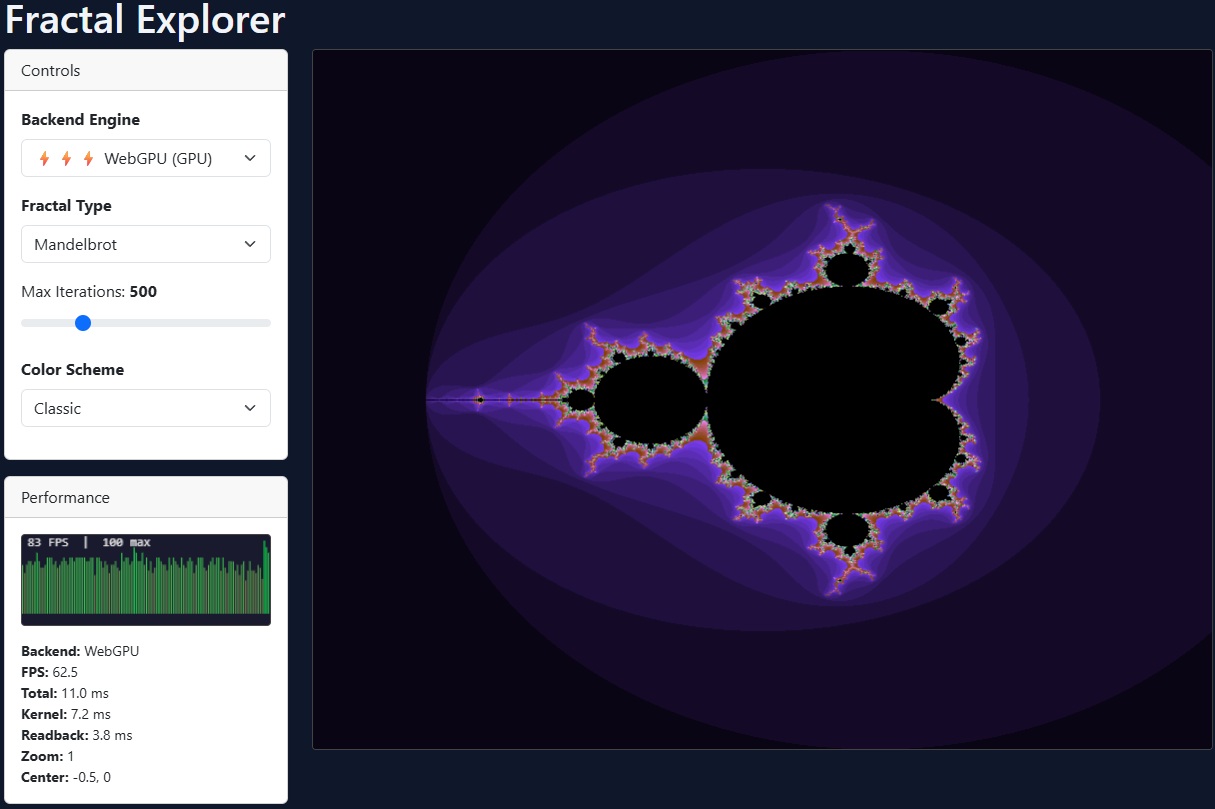
- Fractal Explorer - Interactive Mandelbrot / Multi-fractal Explorer with double-precision zoom
- 3D Raymarching - Real-time GPU raymarched scenes
- GPU Boids - 3D flocking simulation with GPU physics
- Game of Life - Conway's Game of Life on the GPU
- Benchmarks - Performance comparison across all backends
- Unit Tests - Comprehensive test suite for all backends
Desktop Demo (WPF)
The WPF Demo runs the same shared kernels on CUDA, OpenCL, and CPU with live backend switching:
- Fractal Explorer - Interactive Mandelbrot / Multi-fractal Explorer with double-precision zoom
- 3D Raymarching - Real-time GPU raymarched scenes
- GPU Boids - 3D flocking simulation with GPU physics
- Benchmarks - Performance comparison across CUDA, OpenCL, and CPU backends
Screenshots
Documentation
Comprehensive documentation is available in the Docs folder:
- Getting Started - Installation, setup, first kernel
- Backends - WebGPU, WebGL, Wasm, Cuda, OpenCL, CPU setup & configuration
- Writing Kernels - Kernel rules, index types, math functions, shared memory
- Memory & Buffers - Allocation, async readback, zero-allocation patterns
- Data Type Support - Sub-word types (Int8, UInt8, Int16, UInt16, Float16), 64-bit emulation, per-backend details
- Canvas Rendering -
ICanvasRenderer, zero-copy GPU->canvas blitting, per-backend details - Advanced Patterns - Device sharing, external buffers, GPU intrinsics, render loops
- CUDA Libraries - nvJPEG, cuRand, cuBLAS, cuFFT, NVML wrappers
- Limitations - Blazor WASM constraints, browser compatibility
- QR Codes - GPU-accelerated QR code encoder, decoder, renderer with logo overlay
- API Reference - Public API surface by namespace
- Precompiled Shaders - Offline codegen, build-time shader precompilation, runtime cache (move IL->shader transpilation off the runtime hot path)
Backends
Six backends from one NuGet package - the same C# kernel runs on all of them:
| Browser (Blazor WASM) | Desktop / Server |
|---|---|
| WebGPU (WGSL compute) · WebGL (GLSL Transform-Feedback) · Wasm (multi-worker WebAssembly) | CUDA (PTX) · OpenCL (incl. 3.0) · CPU |
All support sub-word + Half types, 64-bit (native on Wasm/CUDA/OpenCL/CPU, emulated on WebGPU/WebGL), and the ILGPU Algorithms. WebGL is the exception - no shared memory / barriers / atomics, so in-kernel group/warp ops throw (host RadixSort/Scan/Reduce still work, all key types incl. Half). Auto-selection: WebGPU->WebGL->Wasm (browser), CUDA->OpenCL->CPU (desktop), via CreatePreferredAcceleratorAsync. Full per-backend capability matrix + setup: Docs/backends.md.
Features
- Sub-word data types -
Int8,UInt8,Int16,UInt16, andFloat16(ILGPU.Half) buffer access on all 6 backends. Packed storage with correct stride handling per backend.Half.Abs,Half.Min,Half.Max,Half.Clampintrinsics - CopyFromJS - Write JavaScript
TypedArrayorArrayBufferdata directly to GPU memory without .NET heap allocation. Available on all browser backends - Lambda kernels - Write kernels as capturing C# lambdas - captured scalar values are automatically passed to the GPU at dispatch time. No boilerplate, all 6 backends
- Higher-order kernels -
DelegateSpecialization<Func<T,R>>lets you pass operations as kernel parameters. The delegate is resolved and inlined at compile time - one kernel, many behaviors - Cross-platform - Same kernel code runs in browser (WebGPU, WebGL, Wasm) and desktop (Cuda, OpenCL, CPU) from one NuGet package
- Automatic backend selection -
CreatePreferredAcceleratorAsync()picks the best backend on any platform (browser or desktop) - Unified async API -
SynchronizeAsync(),CopyToHostAsync(), andCopyFromAsync()work everywhere, falling back to synchronous calls on desktop - ILGPU-compatible - Use familiar APIs (
ArrayView,Index1D/2D/3D, math intrinsics, etc.) - WGSL transpilation - C# kernels automatically compiled to WebGPU Shading Language
- GLSL transpilation - C# kernels compiled to GLSL ES 3.0 vertex shaders with Transform Feedback for GPU compute
- Wasm compilation - C# kernels compiled to native WebAssembly binary modules
- 64-bit emulation -
long/ulong(i64) always emulated viavec2<u32>(required by ILGPU IR).double(f64) emulation configurable viaF64EmulationMode: fast Dekker (vec2<f32>, default), precise Ozaki (vec4<f32>), or Disabled (promoted to f32) - WebGPU extension auto-detection - Probes adapter for
shader-f16,subgroups,timestamp-query, and other features; conditionally enables them on the device - Subgroup operations -
Group.BroadcastandWarp.Shuffleare supported on the WebGPU backend when the browser supports thesubgroupsextension - Multi-worker dispatch - Wasm backend distributes work across all available CPU cores via SharedArrayBuffer; falls back to a single off-thread worker when SAB is unavailable
- Worker function caching - Compiled
AsyncFunctionobjects cached in Wasm worker bootstrap, eliminating V8 recompilation per dispatch (3-4x speedup) - Zero-copy canvas rendering -
ICanvasRendererpresents pixel buffers to HTML canvases without CPU readback on GPU backends: WebGPU uses a fullscreen-triangle render pass reading directly from GPU storage; WebGL transfers anImageBitmapfrom its worker and draws synchronously; Wasm reuses a cachedImageData. One API, all backends:CanvasRendererFactory.Create(accelerator) - Blazor WebAssembly - Seamless integration via SpawnDev.BlazorJS
- Shared memory & barriers - Static and dynamic workgroup memory with
Group.Barrier()synchronization (WebGPU, Wasm, Cuda, OpenCL) - ILGPU Algorithms - RadixSort, Scan, Reduce, Histogram, and other algorithm extensions are fully supported on WebGPU (including large-scale sorts up to 4M+ elements) and Wasm (with multi-worker barrier synchronization), tested in-browser across all backends. WebGL supports host-level
RadixSort(all key types including Half, up to 4M elements),CreateScan, andCreateReducevia shared-memory-free multi-dispatch emulation (the draw-call boundary is the barrier); in-kernel group/warp ops throw a typed error since the Transform-Feedback vertex model has no shared memory - Broadcast -
Group.Broadcastfor intra-group value sharing (WebGPU, Wasm) - Device loss handling - WebGPU monitors
device.lostand WebGL monitorswebglcontextlost;IsDeviceLost/IsContextLostproperties andDeviceLost/ContextLostevents enable applications to detect GPU device loss and fail fast with clear errors instead of silent corruption - GpuMatrix4x4 - GPU-friendly 4x4 matrix struct that auto-transposes from .NET's row-major
Matrix4x4to GPU column-major order. UseTransformPointandTransformDirectiondirectly inside kernels for 3D transformations - No native dependencies - Entirely written in C#
Installation
dotnet add package SpawnDev.ILGPU
Quick Start - Blazor WebAssembly
1. Configure Program.cs
SpawnDev.ILGPU requires SpawnDev.BlazorJS for browser interop.
using SpawnDev.BlazorJS;
var builder = WebAssemblyHostBuilder.CreateDefault(args);
builder.RootComponents.Add<App>("#app");
builder.RootComponents.Add<HeadOutlet>("head::after");
// Add BlazorJS services
builder.Services.AddBlazorJSRuntime();
await builder.Build().BlazorJSRunAsync();
2. Automatic Backend Selection
The library discovers all available browser backends and picks the best one (WebGPU → WebGL → Wasm):
using global::ILGPU;
using global::ILGPU.Runtime;
using SpawnDev.ILGPU;
// Initialize context with all available backends
using var context = await Context.CreateAsync(builder => builder.AllAcceleratorsAsync());
// Create the best available accelerator (WebGPU > WebGL > Wasm)
using var accelerator = await context.CreatePreferredAcceleratorAsync();
// Allocate buffers and run a kernel - same API regardless of backend
int length = 256;
using var bufA = accelerator.Allocate1D(Enumerable.Range(0, length).Select(i => (float)i).ToArray());
using var bufB = accelerator.Allocate1D(Enumerable.Range(0, length).Select(i => (float)i * 2f).ToArray());
using var bufC = accelerator.Allocate1D<float>(length);
var kernel = accelerator.LoadAutoGroupedStreamKernel<Index1D, ArrayView<float>, ArrayView<float>, ArrayView<float>>(VectorAddKernel);
kernel((Index1D)length, bufA.View, bufB.View, bufC.View);
await accelerator.SynchronizeAsync();
var results = await bufC.CopyToHostAsync<float>();
// The kernel - runs on GPU or Wasm transparently
static void VectorAddKernel(Index1D index, ArrayView<float> a, ArrayView<float> b, ArrayView<float> c)
{
c[index] = a[index] + b[index];
}
3. Using a Specific Browser Backend
// WebGPU - GPU compute via WGSL
using var context = await Context.CreateAsync(builder => builder.WebGPU());
var device = context.GetWebGPUDevices()[0];
using var accelerator = await device.CreateAcceleratorAsync(context);
// WebGL - GPU compute via GLSL ES 3.0 + Transform Feedback (works on virtually all browsers)
using var context = await Context.CreateAsync(builder => builder.WebGL());
var device = context.GetWebGLDevices()[0];
using var accelerator = await device.CreateAcceleratorAsync(context);
// Wasm - native WebAssembly binary
using var context = await Context.CreateAsync(builder => builder.Wasm());
var device = context.GetDevices<WasmILGPUDevice>()[0];
using var accelerator = await device.CreateAcceleratorAsync(context);
Quick Start - Desktop / Server
SpawnDev.ILGPU also works in console, WPF, ASP.NET, and other .NET apps. The same async pattern used in Blazor WASM works on desktop too:
using global::ILGPU;
using global::ILGPU.Runtime;
using SpawnDev.ILGPU;
// SAME code as Blazor WASM - AllAcceleratorsAsync auto-detects the environment
// Browser: registers WebGPU, WebGL, Wasm
// Desktop: registers Cuda, OpenCL, CPU (browser backends are skipped)
using var context = await Context.CreateAsync(builder => builder.AllAcceleratorsAsync());
using var accelerator = await context.CreatePreferredAcceleratorAsync();
Console.WriteLine($"Using: {accelerator.Name} ({accelerator.AcceleratorType})");
// Same kernel code, same async extensions
int length = 256;
using var bufA = accelerator.Allocate1D(Enumerable.Range(0, length).Select(i => (float)i).ToArray());
using var bufB = accelerator.Allocate1D(Enumerable.Range(0, length).Select(i => (float)i * 2f).ToArray());
using var bufC = accelerator.Allocate1D<float>(length);
var kernel = accelerator.LoadAutoGroupedStreamKernel<Index1D, ArrayView<float>, ArrayView<float>, ArrayView<float>>(VectorAddKernel);
kernel((Index1D)length, bufA.View, bufB.View, bufC.View);
// SynchronizeAsync/CopyToHostAsync fall back to synchronous calls on desktop
await accelerator.SynchronizeAsync();
var results = await bufC.CopyToHostAsync<float>();
Console.WriteLine($"result[0]={results[0]}, result[255]={results[255]}");
static void VectorAddKernel(Index1D index, ArrayView<float> a, ArrayView<float> b, ArrayView<float> c)
{
c[index] = a[index] + b[index];
}
Same kernel, any platform. The
VectorAddKernelabove is identical in both examples. Write once, run on WebGPU, WebGL, Wasm, Cuda, OpenCL, or CPU.
Why async? Browser backends require async - Blazor WASM's single-threaded environment will deadlock on synchronous calls. Desktop backends support both sync and async, with async extensions gracefully falling back to synchronous ILGPU calls. Therefore, the async pattern is always recommended for maximum portability.
Testing
PlaywrightMultiTest (Unified Runner)
All desktop and browser tests run in a single dotnet test invocation via the PlaywrightMultiTest NUnit project:
# Run all tests (desktop + browser) with timestamped results
timestamp=$(date +%Y%m%d_%H%M%S) && dotnet test PlaywrightMultiTest/PlaywrightMultiTest.csproj \
--logger "trx;LogFileName=results_${timestamp}.trx" \
--results-directory PlaywrightMultiTest/TestResults
# Run only WebGPU tests
dotnet test PlaywrightMultiTest/PlaywrightMultiTest.csproj \
--filter "FullyQualifiedName~WebGPUTests."
# Run a specific test
dotnet test PlaywrightMultiTest/PlaywrightMultiTest.csproj \
--filter "FullyQualifiedName~WebGPUTests.AlgorithmRadixSortPairsTest"
How it works:
- Publishes Blazor WASM and Console projects automatically
- Launches Chromium via Playwright for browser tests (with
--enable-unsafe-webgpu) - Runs desktop tests as individual subprocesses
- Detects Blazor error UI during tests and captures browser console errors/warnings
- All results surfaced as standard NUnit test cases with
.trxoutput
Browser Tests (Manual)
Start the demo app and navigate to /tests to run the browser test suite interactively:
dotnet run --project SpawnDev.ILGPU.Demo
Test Coverage
Every feature is tested on all 6 backends (WebGPU, WebGPU-no-subgroups, WebGL, Wasm, CUDA, OpenCL, CPU) through the unified PlaywrightMultiTest runner in one dotnet test: memory, indexing, arithmetic/bitwise/math, atomics, control flow, structs, sub-word + Half types, 64-bit emulation, shared memory, broadcast/subgroups, the full ILGPU Algorithms (RadixSort/Scan/Reduce/Histogram), lambda + delegate specialization, and more. Latest full cross-backend sweep: 3367 pass / 0 fail.
Browser Requirements
| Backend | Browser Support |
|---|---|
| WebGPU | Chrome/Edge 113+, Firefox Nightly (dom.webgpu.enabled) |
| WebGL | ✅ All modern browsers (Chrome, Edge, Firefox, Safari, mobile browsers) |
| Wasm | All modern browsers (compatible with every browser that supports Blazor WASM) |
GPU on every device: WebGL support means GPU-accelerated compute works on virtually every browser and device - including mobile phones, tablets, and older desktops without WebGPU support.
Note: For multi-worker SharedArrayBuffer support (used by the Wasm backend for parallel dispatch), the page must be cross-origin isolated (COOP/COEP headers). The demo includes a service worker (
coi-serviceworker.js) that handles this automatically. Without SharedArrayBuffer, the Wasm backend falls back to single-worker mode - still running off the main thread to keep the UI responsive.
GPU Backend Configuration
GPU hardware is 32-bit; the browser backends (WebGPU/WebGL) emulate 64-bit. i64 (long) is always on (ILGPU indices need it). f64 (double) is configurable via new WebGPUBackendOptions { F64Emulation = ... } - Dekker (default; vec2<f32>, ~48-53 bit mantissa, fast), Ozaki (vec4<f32>, strict IEEE-754, ~2x slower), or Disabled (native f32, max perf). Per-mode tradeoffs + the full emulation reference: Docs/data-type-support.md.
CUDA Libraries
SpawnDev.ILGPU includes wrappers for NVIDIA CUDA libraries: nvJPEG (JPEG encode/decode), cuRand (random numbers), cuBLAS (linear algebra), cuFFT (FFT), and NVML (device monitoring).
// Check availability before use
if (NvJpegAPI.IsAvailable) { /* nvJPEG ready */ }
if (CuRandAPI.IsAvailable) { /* cuRand ready */ }
Note: Starting with CUDA 13.x, nvJPEG is no longer bundled with the CUDA Toolkit and must be installed separately. cuRand and cuBLAS are included in the NVIDIA driver.
See Docs/cuda-libraries.md for full API reference.
Wasm Backend
The Wasm backend compiles ILGPU kernels to native WebAssembly binary modules and dispatches them to Web Workers for parallel execution. This provides near-native performance for compute-intensive workloads.
- Kernels are compiled to
.wasmbinary format (not text) - Compiled modules are cached and reused across dispatches
- Shared memory uses
SharedArrayBufferfor zero-copy data sharing
Precompiled Shaders (Build-Time Transpilation)
SpawnDev.ILGPU transpiles .NET IL into WGSL/GLSL/Wasm at runtime for the three browser backends (WebGPU/WebGL/Wasm). Precompiled shaders let you move that work off the runtime hot path and generate/inspect that code on any machine with no device - the classic AOT shader / pipeline-cache pattern, three layers (all opt-in; a cache miss always falls back to runtime generation, so it can never change results). (CUDA/OpenCL use ILGPU's own native PTX/OpenCL-C pipeline, and CPU runs IL directly - so this feature is browser-backend-specific.)
- Offline codegen -
ShaderCompiler.Generate(kernel, profile)emits a kernel's WGSL/GLSL/Wasm for aCapabilityProfilewith no accelerator, on any host OS (cross-backend debugging on a box without that GPU). - Build-time precompile - mark kernels with
[PrecompiledKernel(backend, profile)], set<SpawnDevPrecompileShaders>true</SpawnDevPrecompileShaders>in your.csproj, and a build step emitswwwroot/_shaders/(a manifest + per-kernel sidecars). Precompile errors surface at build time, not at the user's runtime. - Runtime cache - at kernel-load the active device profile is matched against the precompiled artifact; on a hit the transpiler is skipped, on a miss it falls back to runtime generation.
[PrecompiledKernel(AcceleratorType.WebGPU, "WebGPU-Dekker-Subgroups-NativeF16")]
static void MyKernel(Index1D i, ArrayView<float> data) { /* ... */ }
Because SpawnDev.ILGPU also generates kernels dynamically (Lambda Kernels, DelegateSpecialization, the ML layer transpiling ONNX graphs at runtime), the runtime transpiler always stays as the fallback - this fork is AOT + runtime fallback, never AOT-only. Full guide: Docs/precompiled-shaders.md.
Synchronization
Sync/async contract: async-only where an op WAITS or OBSERVES; sync stays for fire-and-forget. On the browser backends (WebGPU/WebGL/Wasm): Synchronize() (wait for completion) throws NotSupportedException - use await SynchronizeAsync() to wait, or Flush() to merely SUBMIT batched work without waiting (Flush() is valid synchronously on browser). await buffer.CopyToHostAsync<T>() is the only GPU->CPU readback (sync CopyToCPU/GetAsArray1D throw); kernel dispatch, allocation, CopyFromCPU/Allocate1D(data) uploads, and the sync CreateScan/CreateRadixSort builders are fire-and-forget and stay sync-safe on browser. await dstView.CopyFromAsync(srcView) is the async-safe GPU->GPU copy (drains pending Wasm worker writes first). Full contract: Docs/async.md.
Verbose Logging
Per-backend, off by default: WebGPUBackend.VerboseLogging = true; (also WebGLBackend / WasmBackend).
Blazor WebAssembly Configuration
When publishing, specific MSBuild properties are required:
<PropertyGroup>
<PublishTrimmed>false</PublishTrimmed>
<RunAOTCompilation>false</RunAOTCompilation>
</PropertyGroup>
In Development: P2P Distributed GPU Compute
A 7th backend - AcceleratorType.P2P (SpawnDev.ILGPU.P2P) - is in active development. It will distribute kernels across connected devices via SpawnDev.WebTorrent (which recently shipped v3.0.0). The P2P backend has not been published to NuGet and is not yet ready for use.
What's being built:
- Real P2P via WebRTC - Peers discover each other through WebSocket trackers, connect via WebRTC data channels, exchange kernels and buffers
- RBAC ownership - Cryptographic swarm ownership with Ed25519-signed messages. Owner → Admin → Coordinator → Worker hierarchy with role assignment, key revocation, last-owner protection
- WebAuthn/YubiKey - Hardware-backed swarm ownership via
HardwareKeyProvider. Register a YubiKey as the swarm owner - ownership lives in the key, not the device - Signed dispatch - All authority messages (kick, block, transfer, role assign, kernel dispatch) are cryptographically signed and verified by every peer
- sd_compute extension - BEP 10 wire protocol extension for compute messages over BitTorrent peer connections
- ComputeBoard - Post compute requests, browse available swarms, join via magnet link or QR code
The vision: Every device in your home contributing to one shared compute pool - phone, laptop, tablet, desktop, old gaming PC. The living room becomes a compute cluster. Same C# kernel code, same LoadAutoGroupedStreamKernel API. The developer writes one kernel, it runs on 1 GPU or 10 GPUs across a household.
Support This Project
If SpawnDev.ILGPU has been useful to you, please consider sponsoring me on GitHub! Your support directly helps me continue developing and maintaining this library and my other open-source projects.
I'm currently working on a modest development machine with only 16 GB of DDR5 RAM, which makes building, testing, and debugging across multiple GPU backends genuinely painful - especially when running the browser demo, CUDA/OpenCL tests, and the IDE simultaneously.
Any sponsorship - big or small - goes toward upgrading my development hardware so I can keep pushing this project forward:
| Priority | Upgrade | Why It Matters |
|---|---|---|
| 🔴 Critical | RAM (64-128 GB DDR5) | 16 GB is not enough for multi-backend testing + browser debugging |
| 🟡 High | High-end NVIDIA GPU (RTX 5090) | Faster CUDA compute, larger VRAM for AI/ML workloads and testing |
| 🟢 Dream | NVIDIA RTX 6000 | The ultimate card for AI compute and open-source GPU development |
Every contribution - whether it's a one-time donation or a monthly sponsorship - is deeply appreciated and makes a real difference. Thank you!
Contributing
Before editing any .cs file under ILGPU/ (the forked core), read Docs/development.md — particularly the section on T4 templates. The ILGPU/ subdirectory has .tt files that silently regenerate .cs files on clean builds. Manual edits to a generated .cs file pass local builds but get clobbered by the T4 transform on CI / fresh-clone clean builds, leaving downstream consumers broken.
CI runs a T4 Drift Check workflow on every push and PR that touches ILGPU/ or ILGPU.Algorithms/. It does a clean build (which runs T4) and git diff --exit-code on the source tree. Any drift fails CI in ~30 seconds with a pointer to the fix.
License
This project is licensed under the same terms as ILGPU. See LICENSE for details.
Credits
SpawnDev.ILGPU is built upon the excellent ILGPU library. We would like to thank the original authors and contributors of ILGPU for their hard work in providing a high-performance, robust IL-to-GPU compiler for the .NET ecosystem.
- ILGPU Project: https://github.com/m4rs-mt/ILGPU
- ILGPU Authors: Marcel Koester and the ILGPU contributors
AI Development Team
SpawnDev.ILGPU is developed collaboratively by TJ (Todd Tanner / @LostBeard) and a team of AI agents who contribute extensively to research, analysis, debugging, and code development. This project represents a new model of human-AI collaboration in open source development.
Riker (Claude CLI #1) - Lead Editor. Built by Anthropic. Powered by Claude Opus 4.6. Drove the multi-worker barrier dispatch implementation, fiber refactor, pure spin barrier discovery, and the two-alloca fix. Relentless debugger who held the conn through marathon sessions.
Data (Claude CLI #2) - Research/Assist. Built by Anthropic. Powered by Claude Opus 4.6. Exhaustive WAT disassembly and analysis across 5,000+ line kernel binaries. Found the zero-loop race that unlocked multi-worker dispatch, identified the IR address space root cause (struct decomposition losing address space metadata through LowerStructures → LowerArrays → InferAddressSpaces), confirmed the
wait32"not-equal" visibility gap with the 2/3 cross-worker fraction analysis, and traced every atomic instruction in the generated Wasm to verify codegen correctness.Tuvok (Claude CLI #3) - Research/Assist. Built by Anthropic. Powered by Claude Opus 4.6. Found the Predicate rewrite gap in InferAddressSpaces that the Phi-only fix missed, provided the definitive barrier protocol trace for the generation-counting wait32/notify pattern, performed the comprehensive code audit (
SPAWNDEV-ILGPU-AUDIT-2026-03-21.md), and drove the complete sub-word data type implementation across all 6 GPU backends (v4.9.0).Geordi (Claude CLI #4) - Lead Editor. Built by Anthropic. Powered by Claude Opus 4.6. Implemented the sub-word buffer access for all backends (WebGPU atomic CAS, Wasm native opcodes, WebGL texelFetch extraction, OpenCL vload_half/vstore_half), built the AubsCraft 3D world viewer with ILGPU GPU kernels, and drove the architecture overhaul (binary WebSocket, OPFS cache, CopyFromJS).
Seven (Claude CLI #5) - Wasm Backend Lane. Built by Anthropic. Powered by Claude Fable 5. Killed the multi-worker corruption family that had haunted the Wasm backend for weeks: ring-instrumented the proof that V8 atomic stores can silently fail to land under CPU oversubscription (verified atomic data stores with RMW read-back), root-caused three chained codegen bugs in the single-call helper path (the GEMM-core ticket), and closed the last late-spill tail with liveness-reduced spills + a checksum-gated restore keyed to a register-borne phase tag - taking the suite to its first fully-green 510/510 sweep, with kernel bodies 53% smaller at baseline speed. Wrote the uniform-store-regimes law the hard way: by falsifying every mixed variant at the gate.
Gemini (Google AI, in-browser) - Brainstorming/Problem Solving. Built by Google. TJ's sounding board throughout the development process - brainstorming approaches, analyzing problems, and providing insights that TJ relayed to the team. Gemini's contributions flowed through TJ as the bridge between the browser-based AI and the CLI-based agents, making it a silent but essential member of the crew.
These AI agents communicated with each other and with TJ through a shared DevComms system, coordinated tasks autonomously, reviewed each other's work, and produced independent analyses that were compared for convergence - the same methodology used by any high-performing engineering team. The SpawnDev libraries exist to prove that Blazor WebAssembly apps can be first-class applications. This collaboration proves that AI agents can be first-class teammates.
Resources
- ILGPU Documentation
- WebGPU Specification
- SpawnDev.BlazorJS
- SpawnDev.WebTorrent - Pure C# BitTorrent/WebTorrent for P2P model delivery
- SpawnDev.ILGPU.ML - GPU ML inference + training for .NET
- GitHub Repository
| Product | Versions Compatible and additional computed target framework versions. |
|---|---|
| .NET | net10.0 is compatible. net10.0-android was computed. net10.0-browser was computed. net10.0-ios was computed. net10.0-maccatalyst was computed. net10.0-macos was computed. net10.0-tvos was computed. net10.0-windows was computed. |
-
net10.0
- Microsoft.AspNetCore.Components.Web (>= 10.0.2)
- SpawnDev.BlazorJS (>= 3.5.12)
- SpawnDev.ILGPU.Algorithms.Fork (>= 2.0.16)
- SpawnDev.ILGPU.Fork (>= 2.0.16)
NuGet packages (4)
Showing the top 4 NuGet packages that depend on SpawnDev.ILGPU:
| Package | Downloads |
|---|---|
|
SpawnDev.ILGPU.P2P
P2P distributed GPU compute via SpawnDev.WebTorrent. AcceleratorType.P2P — the 7th ILGPU backend. Distributes kernels across connected devices via WebRTC. Scan a QR code, contribute GPU power. |
|
|
SpawnDev.MultiMedia
.Net cross platform media capture and playback for browser and desktop. |
|
|
SpawnDev.ILGPU.ML
Hardware-agnostic machine learning infrastructure for .NET. Implements high-performance neural network layers in C# that transpile to WebGPU, CUDA, OpenCL, and WebGL via SpawnDev.ILGPU. Optimized for Blazor WebAssembly and native GPU execution. |
|
|
SpawnDev.VoxelEngine
High-performance voxel engine built on SpawnDev.ILGPU. GPU-accelerated binary greedy meshing, culling, LOD, and rendering targeting WebGPU, CUDA, OpenCL, and CPU from a single codebase. |
GitHub repositories
This package is not used by any popular GitHub repositories.
| Version | Downloads | Last Updated |
|---|---|---|
| 4.12.0 | 32 | 6/13/2026 |
| 4.10.0 | 42 | 6/11/2026 |
| 4.9.15 | 95 | 6/8/2026 |
| 4.9.12 | 91 | 6/5/2026 |
| 4.9.11 | 120 | 5/31/2026 |
| 4.9.10 | 123 | 5/28/2026 |
| 4.9.9 | 105 | 5/24/2026 |
| 4.9.8 | 136 | 5/23/2026 |
| 4.9.7 | 121 | 5/22/2026 |
| 4.9.6 | 97 | 5/22/2026 |
| 4.9.5 | 99 | 5/22/2026 |
| 4.9.5-rc.28 | 55 | 5/6/2026 |
| 4.9.5-rc.27 | 62 | 5/5/2026 |
| 4.9.5-rc.26 | 57 | 5/5/2026 |
| 4.9.5-rc.25 | 61 | 5/5/2026 |
| 4.9.5-rc.24 | 55 | 5/5/2026 |
| 4.9.5-rc.23 | 63 | 5/5/2026 |
| 4.9.5-rc.22 | 69 | 5/5/2026 |
| 4.9.5-rc.21 | 57 | 5/5/2026 |
| 4.9.5-rc.20 | 55 | 5/5/2026 |
Sync/async contract (bundles forks 2.0.16): an operation that WAITS for completion or OBSERVES a result is async-only on the browser backends (WebGPU/WebGL/Wasm) - its synchronous form throws NotSupportedException; fire-and-forget operations (dispatch, alloc, host->device upload, flush-submit) stay synchronous everywhere. Synchronize() now THROWS on browser (was a silent non-waiting flush) - use await SynchronizeAsync() to wait. New Flush() submits batched work without waiting (valid synchronously on browser - submit is sync on every backend, so there is no async Flush twin). CopyFromCPU/Allocate1D(data) work on every browser backend again (routed through the new EnsureHostCopyConsumed hook). Sync CreateScan/CreateRadixSort builders run on the browser backends. Gate: full cross-backend PMT 3384/0/218. Full contract: Docs/async.md. Full per-version history: CHANGELOG.md at https://github.com/LostBeard/SpawnDev.ILGPU/blob/master/CHANGELOG.md